Writing Evaluation Script
Writing an Evaluation Script
Each challenge has an evaluation script, which evaluates the submission of participants and returns the scores which will populate the leaderboard. The logic for evaluating and judging a submission is customizable and varies from challenge to challenge, but the overall structure of evaluation scripts are fixed due to architectural reasons.
Evaluation scripts are required to have an evaluate() function. This is the main function, which is used by workers to evaluate the submission messages.
The syntax of evaluate function is:
def evaluate(test_annotation_file, user_annotation_file, phase_codename, **kwargs):
pass
It receives three arguments, namely:
test_annotation_file: It represents the local path to the annotation file for the challenge. This is the file uploaded by the Challenge host while creating a challenge.user_annotation_file: It represents the local path of the file submitted by the user for a particular challenge phase.phase_codename: It is thecodenameof the challenge phase from the challenge configuration yaml. This is passed as an argument so that the script can take actions according to the challenge phase.
After reading the files, some custom actions can be performed. This varies per challenge.
The evaluate() method also accepts keyword arguments. By default, we provide you metadata of each submission to your challenge which you can use to send notifications to your slack channel or to some other webhook service. Following is an example code showing how to get the submission metadata in your evaluation script and send a slack notification if the accuracy is more than some value X (X being 90 in the example given below).
def evaluate(test_annotation_file, user_annotation_file, phase_codename, **kwargs):
submission_metadata = kwargs.get("submission_metadata")
print submission_metadata
# Do stuff here
# Set `score` to 91 as an example
score = 91
if score > 90:
slack_data = kwargs.get("submission_metadata")
webhook_url = "Your slack webhook url comes here"
# To know more about slack webhook, checkout this link: https://api.slack.com/incoming-webhooks
response = requests.post(
webhook_url,
data=json.dumps({'text': "*Flag raised for submission:* \n \n" + str(slack_data)}),
headers={'Content-Type': 'application/json'})
# Do more stuff here
The above example can be modified and used to find if some participant team is cheating or not. There are many more ways for which you can use this metadata.
After all the processing is done, this evaluate() should return an output, which is used to populate the leaderboard. The output should be in the following format:
output = {}
output['result'] = [
{
'train_split': {
'Metric1': 123,
'Metric2': 123,
'Metric3': 123,
'Total': 123,
}
},
{
'test_split': {
'Metric1': 123,
'Metric2': 123,
'Metric3': 123,
'Total': 123,
}
}
]
return output
Let’s break down what is happening in the above code snippet.
outputshould contain a key namedresult, which is a list containing entries per dataset split that is available for the challenge phase in consideration (in the function definition ofevaluate()shown above, the argument:phase_codenamewill receive the codename for the challenge phase against which the submission was made).Each entry in the list should be a dict that has a key with the corresponding dataset split codename (
train_splitandtest_splitfor this example).Each of these dataset split dict contains various keys (
Metric1,Metric2,Metric3,Totalin this example), which are then displayed as columns in the leaderboard.
Writing Remote Evaluation Script
Each challenge has an evaluation script, which evaluates the submission of participants and returns the scores which will populate the leaderboard. The logic for evaluating and judging a submission is customizable and varies from challenge to challenge, but the overall structure of evaluation scripts is fixed due to architectural reasons.
The starter template for remote challenge evaluation can be found here.
Here are the steps to configure remote evaluation:
Setup Configs:
To configure authentication for the challenge set the following environment variables:
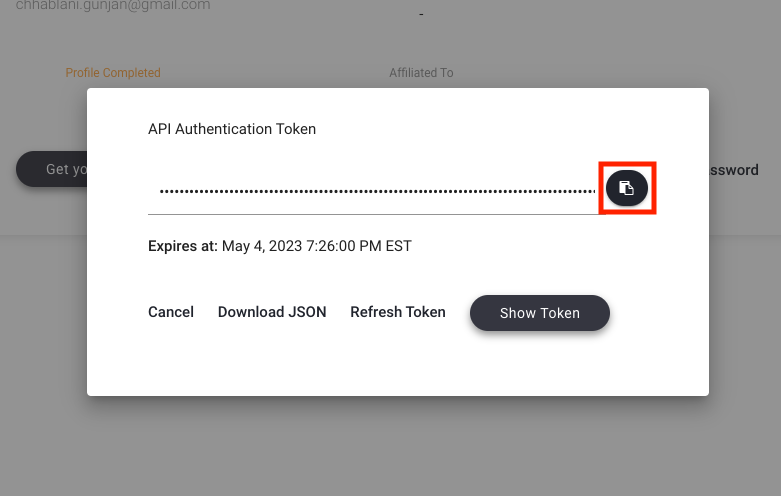
AUTH_TOKEN: Go to profile page -> Click on
Get your Auth Token-> Click on the Copy button. The auth token will get copied to your clipboard.API_SERVER: Use
https://eval.aiwhen setting up challenge on production server. Otherwise, usehttps://staging.eval.ai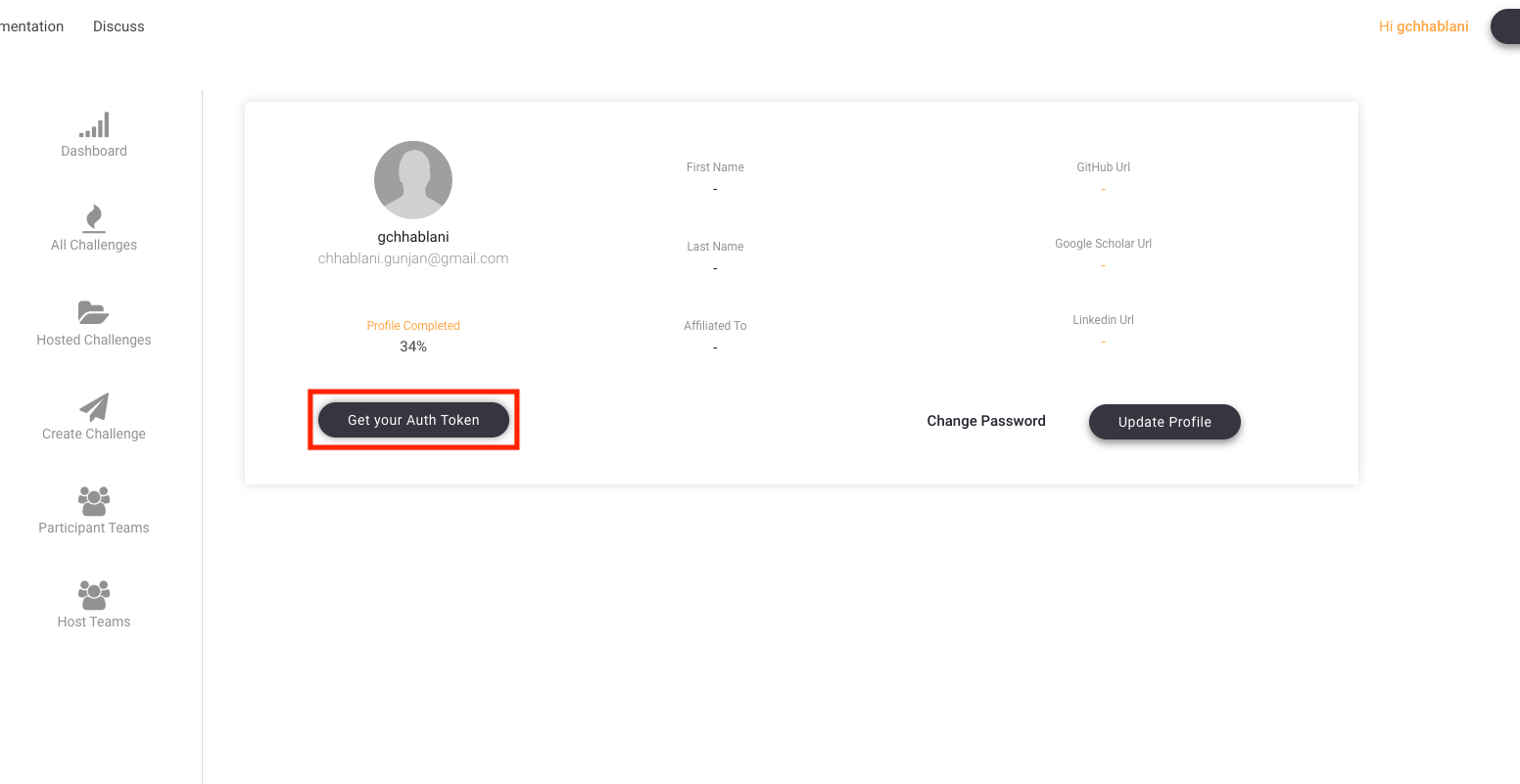
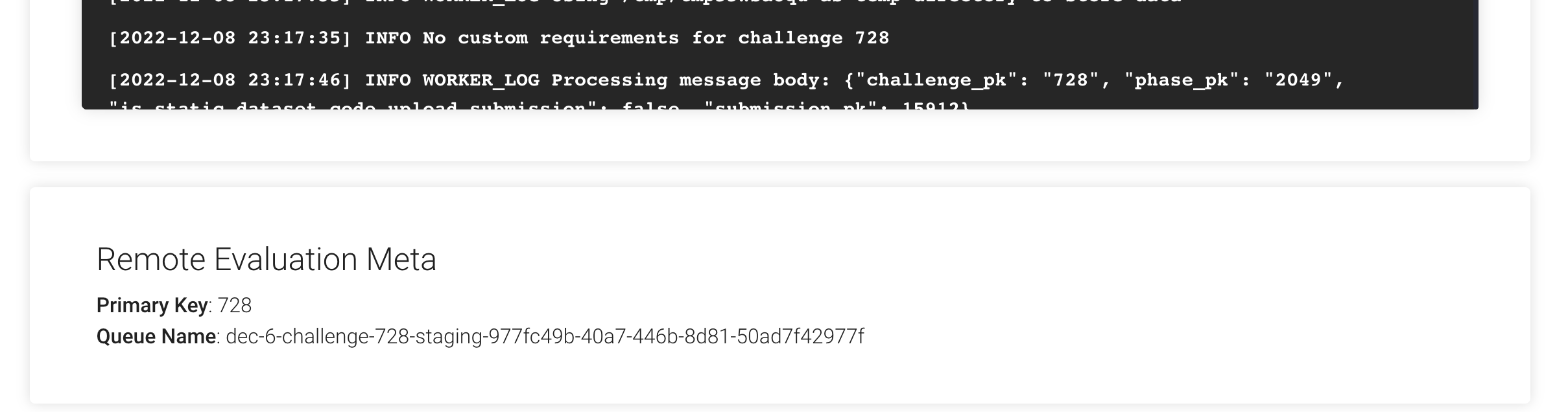
QUEUE_NAME: Go to the challenge manage tab to fetch the challenge queue name.
CHALLENGE_PK: Go to the challenge manage tab to fetch the challenge primary key.
SAVE_DIR: (Optional) Path to submission data download location.
Write
evaluatemethod: Evaluation scripts are required to have anevaluate()function. This is the main function, which is used by workers to evaluate the submission messages.The syntax of evaluate function for a remote challenge is:
def evaluate(user_submission_file, phase_codename, test_annotation_file = None, **kwargs) pass
It receives three arguments, namely:
user_annotation_file: It represents the local path of the file submitted by the user for a particular challenge phase.phase_codename: It is thecodenameof the challenge phase from the challenge configuration yaml. This is passed as an argument so that the script can take actions according to the challenge phase.test_annotation_file: It represents the local path to the annotation file for the challenge. This is the file uploaded by the Challenge host while creating a challenge.
You may pass the
test_annotation_fileas default argument or choose to pass separately in themain.pydepending on the case. Thephase_codenameis passed automatically but is left as an argument to allow customization.After reading the files, some custom actions can be performed. This varies per challenge.
The
evaluate()method also accepts keyword arguments.IMPORTANT ⚠️: If the
evaluate()method fails due to any reason or there is a problem with the submission, please ensure to raise anExceptionwith an appropriate message.